Sort Extension Connector
Overview
InLong Sort is an ETL service based on Apache Flink SQL, the powerful expressive power of Flink SQL brings high scalability and flexibility. Basically, the semantics supported by Flink SQL are supported by InLong Sort. In some scenarios, when the built-in functions of Flink SQL do not meet the requirements, they can also be extended through various UDFs in InLong Sort. At the same time, it will be easier for those who have used SQL, especially Flink SQL, to get started.
This article describes how to extend a new source (abstracted as extract node in inlong) or a new sink (abstracted as load node in inlong) in InLong Sort. The architecture of inlong sort can be represented by UML object relation diagram as:
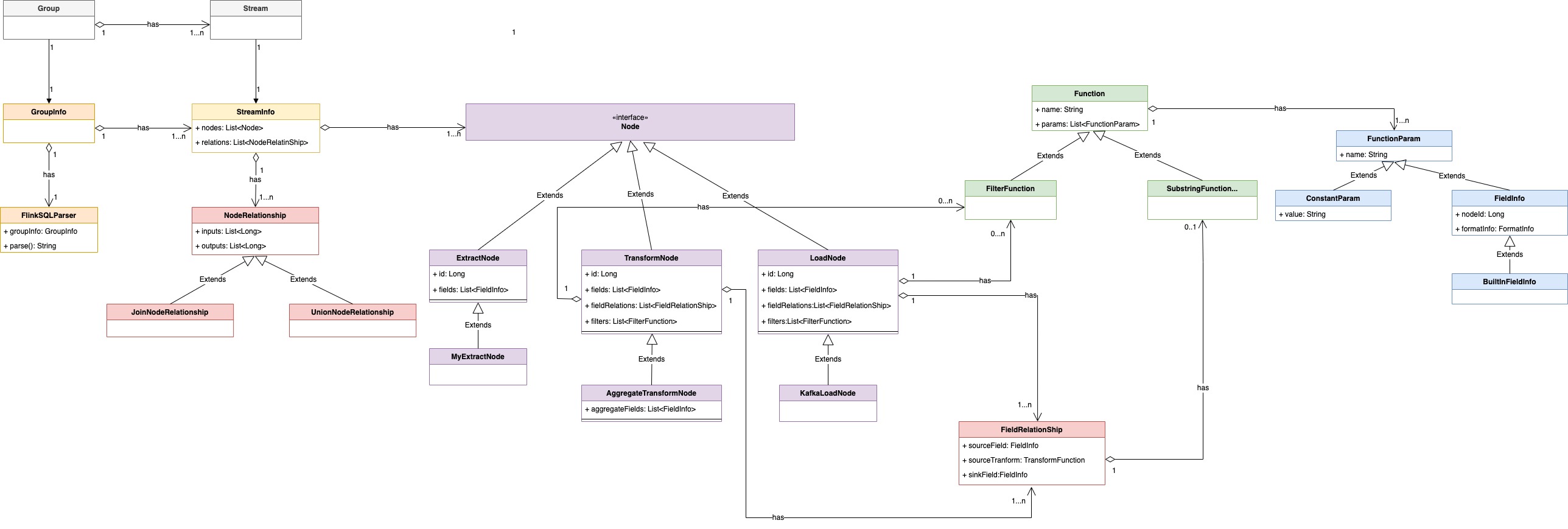
The concepts of each component are:
| Name | Description |
|---|---|
| Group | data flow group, including multiple data flows, one group represents one data access |
| Stream | data flow, a data flow has a specific flow direction |
| GroupInfo | encapsulation of data flow in sort. a groupinfo can contain multiple dataflowinfo |
| StreamInfo | abstract of data flow in sort, including various sources, transformations, destinations, etc. |
| Node | abstraction of data source, data transformation and data destination in data synchronization |
| ExtractNode | source-side abstraction for data synchronization |
| TransformNode | transformation process abstraction of data synchronization |
| LoadNode | destination abstraction for data synchronization |
| NodeRelationShip | abstraction of each node relationship in data synchronization |
| FieldRelationShip | abstraction of the relationship between upstream and downstream node fields in data synchronization |
| FieldInfo | node field |
| MetaFieldInfo | node meta fields |
| Function | abstraction of transformation function |
| FunctionParam | input parameter abstraction of function |
| ConstantParam | constant parameters |
Extending Extract & Load Node
The Extract nodes is a set of Source Connectors based on Apache Flink® used to extract data from different source systems. The Load nodes is a set of Sink Connectors based on Apache Flink® used to load data into different storage systems.
When Apache InLong Sort starts, it translates a set of Extract and Load Node configurations into corresponding Flink SQL and submits them to the Flink cluster, initiating the data extraction and loading tasks specified by the user.
Adding Extract & Load Node Definitions
To customize an Extract Node, you need to inherit the org.apache.inlong.sort.protocol.node.ExtractNode class, and to customize a Load Node, you need to inherit the org.apache.inlong.sort.protocol.node.LoadNode class. Both must selectively implement methods from the org.apache.inlong.sort.protocol.node.Node interface.
| Method Name | Meaning | Default Value |
|---|---|---|
| getId | Get node ID | Inlong StreamSource Id |
| getName | Get node name | Inlong StreamSource Name |
| getFields | Get field information | Fields defined by Inlong Stream |
| getProperties | Get additional node properties | Empty Map |
| tableOptions | Get Flink SQL table properties | Additional node properties |
| genTableName | Generate Flink SQL table name | No default value |
| getPrimaryKey | Get primary key | null |
| getPartitionFields | Get partition fields | null |
Extend Extract Node
There are three steps to extend an ExtractNode:
Step 1:Inherit the ExtractNode class,the location of the class is:
inlong-sort/sort-common/src/main/java/org/apache/inlong/sort/protocol/node/ExtractNode.java
Specify the connector in the implemented ExtractNode.
// Inherit ExtractNode class and implement specific classes, such as MongoExtractNode
@EqualsAndHashCode(callSuper = true)
@JsonTypeName("MongoExtract")
@Data
public class MongoExtractNode extends ExtractNode implements Serializable {
@JsonInclude(Include.NON_NULL)
@JsonProperty("primaryKey")
private String primaryKey;
...
@JsonCreator
public MongoExtractNode(@JsonProperty("id") String id, ...) { ... }
@Override
public Map<String, String> tableOptions() {
Map<String, String> options = super.tableOptions();
// configure the specified connector, here is mongodb-cdc
options.put("connector", "mongodb-cdc");
...
return options;
}
}
Step 2:add the Extract to JsonSubTypes in ExtractNode and Node
// add field in JsonSubTypes of ExtractNode and Node
...
@JsonSubTypes({
@JsonSubTypes.Type(value = MongoExtractNode.class, name = "mongoExtract")
})
...
public abstract class ExtractNode implements Node{...}
...
@JsonSubTypes({
@JsonSubTypes.Type(value = MongoExtractNode.class, name = "mongoExtract")
})
public interface Node {...}
Step 3:Expand the Sort connector and check whether the corresponding connector already exists in the (InLong Agentinlong-sort/sort-connectors/mongodb-cdc) directory. If you haven't already,
you need to refer to the official flink documentation DataStream Connectors to extend,
directly call the existing flink-connector (such asinlong-sort/sort-connectors/mongodb-cdc) or implement the related connector by yourself.
Extend Load Node
There are three steps to extend an LoadNode:
Step 1:Inherit the LoadNode class, the location of the class is:
inlong-sort/sort-common/src/main/java/org/apache/inlong/sort/protocol/node/LoadNode.java
specify the connector in the implemented LoadNode.
// Inherit LoadNode class and implement specific classes, such as KafkaLoadNode
@EqualsAndHashCode(callSuper = true)
@JsonTypeName("kafkaLoad")
@Data
@NoArgsConstructor
public class KafkaLoadNode extends LoadNode implements Serializable {
@Nonnull
@JsonProperty("topic")
private String topic;
...
@JsonCreator
public KafkaLoadNode(@Nonnull @JsonProperty("topic") String topic, ...) {...}
// configure and use different connectors according to different conditions
@Override
public Map<String, String> tableOptions() {
...
if (format instanceof JsonFormat || format instanceof AvroFormat || format instanceof CsvFormat) {
if (StringUtils.isEmpty(this.primaryKey)) {
// kafka connector
options.put("connector", "kafka");
options.putAll(format.generateOptions(false));
} else {
options.put("connector", "upsert-kafka"); // upsert-kafka connector
options.putAll(format.generateOptions(true));
}
} else if (format instanceof CanalJsonFormat || format instanceof DebeziumJsonFormat) {
// kafka-inlong connector
options.put("connector", "kafka-inlong");
options.putAll(format.generateOptions(false));
} else {
throw new IllegalArgumentException("kafka load Node format is IllegalArgument");
}
return options;
}
}
Step 2:add the Load to JsonSubTypes in ExtractNode and Node
// add field in JsonSubTypes of LoadNode and Node
...
@JsonSubTypes({
@JsonSubTypes.Type(value = KafkaLoadNode.class, name = "kafkaLoad")
})
...
public abstract class LoadNode implements Node{...}
...
@JsonSubTypes({
@JsonSubTypes.Type(value = KafkaLoadNode.class, name = "kafkaLoad")
})
public interface Node {...}
Step 3:Extend the Sort connector, Kafka's sort connector is in inlong-sort/sort-connectors/kafka.
Integrate Entrance
To integrate extract and load into the InLong Sort mainstream, you need to implement the semantics mentioned in the overview section: group, stream, node, etc. The entry class of InLong Sort is in :
inlong-sort/sort-core/src/main/java/org/apache/inlong/sort/Entrance.java
How to integrate extract and load into InLong Sort can refer to the following ut. First, build the corresponding extractnode and loadnode, then build noderelation, streaminfo and groupinfo, and finally use FlinkSqlParser to execute.
public class MongoExtractToKafkaLoad extends AbstractTestBase {
// create MongoExtractNode
private MongoExtractNode buildMongoNode() {
List<FieldInfo> fields = Arrays.asList(new FieldInfo("name", new StringFormatInfo()), ...);
return new MongoExtractNode(..., fields, ...);
}
// create KafkaLoadNode
private KafkaLoadNode buildAllMigrateKafkaNode() {
List<FieldInfo> fields = Arrays.asList(new FieldInfo("name", new StringFormatInfo()), ...);
List<FieldRelation> relations = Arrays.asList(new FieldRelation(new FieldInfo("name", new StringFormatInfo()), ...), ...);
CsvFormat csvFormat = new CsvFormat();
return new KafkaLoadNode(..., fields, relations, csvFormat, ...);
}
// create NodeRelation
private NodeRelation buildNodeRelation(List<Node> inputs, List<Node> outputs) {
List<String> inputIds = inputs.stream().map(Node::getId).collect(Collectors.toList());
List<String> outputIds = outputs.stream().map(Node::getId).collect(Collectors.toList());
return new NodeRelation(inputIds, outputIds);
}
// test the main flow: mongodb to kafka
@Test
public void testMongoDbToKafka() throws Exception {
EnvironmentSettings settings = EnvironmentSettings. ... .build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
...
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
Node inputNode = buildMongoNode();
Node outputNode = buildAllMigrateKafkaNode();
StreamInfo streamInfo = new StreamInfo("1", Arrays.asList(inputNode, outputNode), ...);
GroupInfo groupInfo = new GroupInfo("1", Collections.singletonList(streamInfo));
FlinkSqlParser parser = FlinkSqlParser.getInstance(tableEnv, groupInfo);
ParseResult result = parser.parse();
Assert.assertTrue(result.tryExecute());
}
}
Additionally, Sort has added two extra interfaces, InlongMetric and Metadata, to support richer semantics.
InlongMetric
If a custom node needs to report Inlong metrics, it must implement the org.apache.inlong.sort.protocol.InlongMetric interface.
When Sort parses the configuration, it adds the startup parameter 'inlong.metric.labels' = 'groupId={g}&streamId={s}&nodeId={n}' to the table option, which is used to configure Inlong Audit.
For details, see How to Integrate Inlong Audit into Custom Connector
Metadata
If a custom node needs to specify a field as a Flink SQL Metadata field, it must implement the org.apache.inlong.sort.protocol.Metadata interface.
Sort will automatically mark the corresponding field as Metadata when parsing the configuration.
Extending Apache Flink Connector
Sort is implemented based on Apache Flink version 1.15. For information on how to extend the Apache Flink Connector, refer to User-defined Sources & Sinks
How to Integrate Inlong Audit into Custom Connector
Inlong Sort encapsulates the metric reporting process in the org.apache.inlong.sort.base.metric.SourceExactlyMetric and org.apache.inlong.sort.base.metric.SinkExactlyMetric classes. Developers only need to initialize the corresponding Metric object according to the Source/Sink type to implement metric reporting.
The common practice is to pass parameters such as the InLong Audit address when constructing the Source/Sink, and initialize the SourceExactlyMetric/SinkExactlyMetric object when calling the open() method to initialize the Source/Sink operator. After processing the actual data, call the corresponding audit reporting method.
public class StarRocksDynamicSinkFunctionV2<T> extends StarRocksDynamicSinkFunctionBase<T> {
private static final long serialVersionUID = 1L;
private static final Logger log = LoggerFactory.getLogger(StarRocksDynamicSinkFunctionV2.class);
private transient SinkExactlyMetric sinkExactlyMetric;
private String inlongMetric;
private String auditHostAndPorts;
private String auditKeys;
private String stateKey;
public StarRocksDynamicSinkFunctionV2(StarRocksSinkOptions sinkOptions,
TableSchema schema,
StarRocksIRowTransformer<T> rowTransformer, String inlongMetric,
String auditHostAndPorts, String auditKeys) {
this.sinkOptions = sinkOptions;
// pass the params of inlong audit
this.auditHostAndPorts = auditHostAndPorts;
this.inlongMetric = inlongMetric;
this.auditKeys = auditKeys;
}
@Override
public void open(Configuration parameters) {
// init SinkExactlyMetric in open()
MetricOption metricOption = MetricOption.builder().withInlongLabels(inlongMetric)
.withAuditAddress(auditHostAndPorts)
.withAuditKeys(auditKeys)
.build();
if (metricOption != null) {
sinkExactlyMetric = new SinkExactlyMetric(metricOption, getRuntimeContext().getMetricGroup());
}
}
@Override
public void invoke(T value, Context context)
throws IOException, ClassNotFoundException, JSQLParserException {
Object[] data = rowTransformer.transform(value, sinkOptions.supportUpsertDelete());
sinkManager.write(
null,
sinkOptions.getDatabaseName(),
sinkOptions.getTableName(),
serializer.serialize(schemaUtils.filterOutTimeField(data)));
// output audit after write data to sink
if (sinkExactlyPropagateMetric != null) {
sinkExactlyPropagateMetric.invoke(1, getDataSize(value), schemaUtils.getDataTime(data));
}
}
}