Iceberg
Overview
Apache Iceberg is a high-performance format for huge analytic tables.
Version
| Extract Node | Version |
|---|---|
| Iceberg | Iceberg: 0.12.x, 0.13.x |
Dependencies
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-iceberg</artifactId>
<version>1.13.0-SNAPSHOT</version>
</dependency>
Usage
Before creating the Iceberg task, we need a Flink environment integrated with Hadoop.
- Download
Apache Hadoop. - Modify
jobmanager.shandtaskmanager.shand addHadoopenvironment variables. For commands, please refer to Apache Flink.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
- Modify
docker-compose.ymlin thedocker/docker-composeand mountHadoopandFlink startup commandsinto the container:
jobmanager:
image: apache/flink:1.13-scala_2.11
container_name: jobmanager
user: root
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
volumes:
# Mount Hadoop
- HADOOP_HOME:HADOOP_HOME
# Mount the modified jobmanager.sh which adds the HADOOP_HOME env correctly
- /jobmanager.sh:/opt/flink/bin/jobmanager.sh
ports:
- "8081:8081"
command: jobmanager
taskmanager:
image: apache/flink:1.13-scala_2.11
container_name: taskmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 2
volumes:
# Mount Hadoop
- HADOOP_HOME:HADOOP_HOME
# Mount the modified taskmanager.sh which adds the HADOOP_HOME env correctly
- /taskmanager.sh:/opt/flink/bin/taskmanager.sh
command: taskmanager
Flink SQL API
Before using Flink sql client, sql-client.sh also needs to add Hadoop environment variables and mounted to the container.
For commands, please refer to Apache Flink.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
使用 Flink sql cli:
CREATE TABLE `iceberg_table_source`(
PRIMARY KEY (`_id`) NOT ENFORCED,
`_id` STRING,
`id` INT,
`name` STRING,
`age` INT)
WITH (
'connector' = 'iceberg-inlong',
'catalog-database' = 'DATABASES',
'catalog-table' = 'TABLE',
'catalog-type' = 'HIVE',
'catalog-name' = 'HIVE',
'streaming' = 'true',
'uri' = 'thrift://127.0.0.1:9083'
);
Dashboard
Source → Create → Iceberg
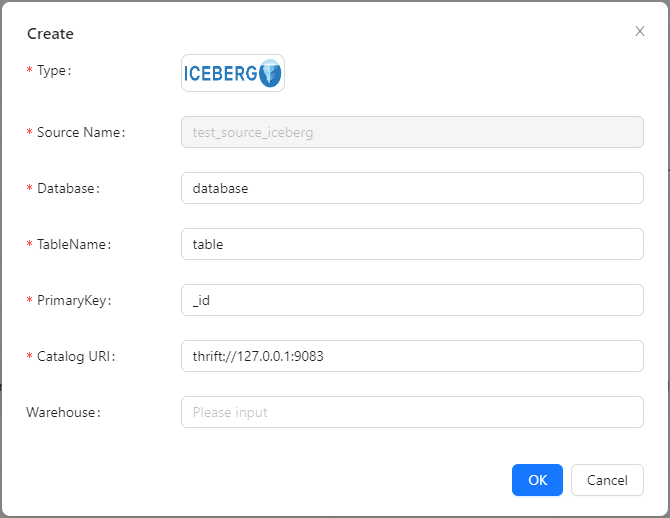
Manager Client
TODO
Options
| Options | Required | Type | Description |
|---|---|---|---|
| connector | required | String | Specify what connector to use, here should be 'iceberg-inlong' |
| catalog-database | required | String | Database name managed in the Iceberg directory |
| catalog-table | required | String | Table name managed in Iceberg catalogs and databases |
| catalog-type | required | String | hive or hadoop for built-in directories |
| catalog-name | required | String | directory name |
| uri | required | String | The thrift URI of Hive metastore, such as: thrift://127.0.0.1:9083 |
| warehouse | optional | String | For a Hive directory, the Hive repository location. For the hadoop directory, it is the HDFS directory that stores metadata files and data files. |
| inlong.metric.labels | optional | String | In long metric label, the format of value is groupId=xxgroup&streamId=xxstream&nodeId=xxnode |
Data Type Mapping
| Flink SQL Type | Iceberg Type |
|---|---|
| CHAR | STRING |
| VARCHAR | STRING |
| STRING | STRING |
| BOOLEAN | BOOLEAN |
| BINARY | FIXED(L) |
| VARBINARY | BINARY |
| DECIMAL | DECIMAL(P,S) |
| TINYINT | INT |
| SMALLINT | INT |
| INTEGER | INT |
| BIGINT | LONG |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DATE | DATE |
| TIME | TIME |
| TIMESTAMP | TIMESTAMP |
| TIMESTAMP_LTZ | TIMESTAMPTZ |
| INTERVAL | - |
| ARRAY | LIST |
| MULTISET | MAP |
| MAP | MAP |
| ROW | STRUCT |
| RAW | - |