ClickHouse
概览
ClickHouse Load 节点支持将数据写入 ClickHouse 数据库。 本文档介绍如何设置 ClickHouse Load 节点以对 ClickHouse 数据库运行 SQL 查询。
支持的版本
| Load 节点 | Driver | Group Id | Artifact Id | JAR |
|---|---|---|---|---|
| ClickHouse | ClickHouse | ru.yandex.clickhouse | clickhouse-jdbc | 下载 |
依赖
为了设置 ClickHouse Load 节点, 下面提供了使用构建自动化工具(例如 Maven 或 SBT)和带有 Sort Connector JAR 包的 SQL 客户端的两个项目的依赖关系信息。
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-jdbc</artifactId>
<version>1.13.0-SNAPSHOT</version>
</dependency>
如何创建 ClickHouse Load 节点
SQL API 用法
-- MySQL Extract 节点
CREATE TABLE `mysql_extract_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'mysql-cdc-inlong',
'url' = 'jdbc:mysql://localhost:3306/read',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'user'
)
-- ClickHouse Load 节点
CREATE TABLE `clickhouse_load_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'jdbc-inlong',
'dialect-impl' = 'org.apache.inlong.sort.jdbc.dialect.ClickHouseDialect',
'url' = 'jdbc:clickhouse://localhost:8123/demo',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'demo.user'
)
-- 写数据到 ClickHouse
INSERT INTO clickhouse_load_table
SELECT id, name , age FROM mysql_extract_table;
InLong Dashboard 用法
创建数据流时,数据流方向选择ClickHouse,点击“添加”进行配置。
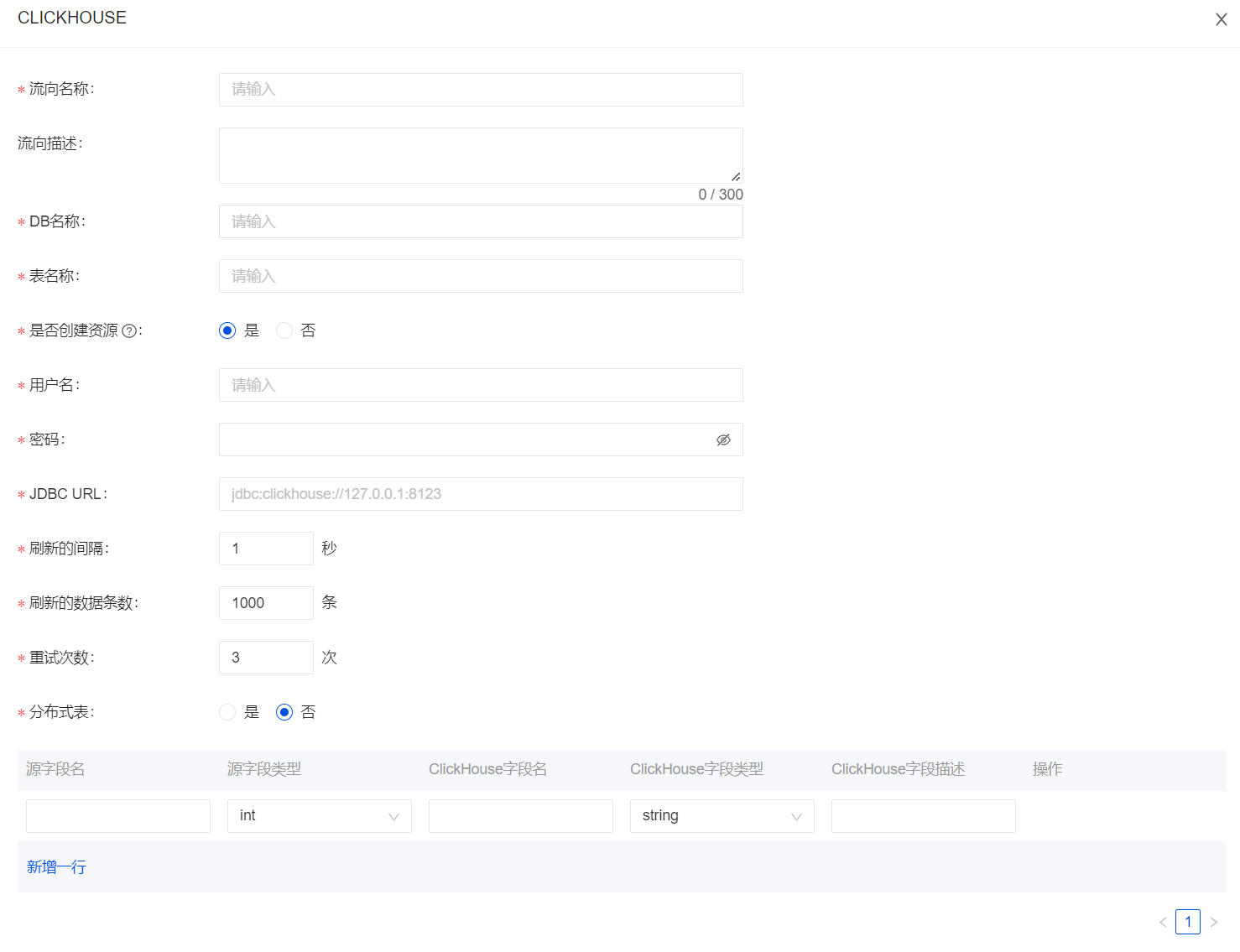
InLong Manager Client 用法
TODO: 将在未来支持此功能。
ClickHouse Load 节点参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (none) | String | 指定使用什么类型的连接器,这里应该是 'jdbc-inlong'。 |
| url | 必选 | (none) | String | JDBC 数据库 url。 |
| dialect-impl | 必选 | (none) | String | org.apache.inlong.sort.jdbc.dialect.ClickHouseDialect |
| table-name | 必选 | (none) | String | 连接到 JDBC 表的名称。例子:database.tableName |
| driver | 可选 | (none) | String | 用于连接到此 URL 的 JDBC 驱动类名,如果不设置,将自动从 URL 中推导。 |
| username | 可选 | (none) | String | JDBC 用户名。如果指定了 'username' 和 'password' 中的任一参数,则两者必须都被指定。 |
| password | 可选 | (none) | String | JDBC 密码。 |
| connection.max-retry-timeout | 可选 | 60s | Duration | 最大重试超时时间,以秒为单位且不应该小于 1 秒。 |
| sink.buffer-flush.max-rows | 可选 | 100 | Integer | flush 前缓存记录的最大值,可以设置为 '0' 来禁用它。 |
| sink.buffer-flush.interval | 可选 | 1s | Duration | flush 间隔时间,超过该时间后异步线程将 flush 数据。可以设置为 '0' 来禁用它。注意, 为了完全异步地处理缓存的 flush 事件,可以将 'sink.buffer-flush.max-rows' 设置为 '0' 并配置适当的 flush 时间间隔。 |
| sink.max-retries | 可选 | 3 | Integer | 写入记录到数据库失败后的最大重试次数。 |
| sink.parallelism | 可选 | (none) | Integer | 用于定义 JDBC sink 算子的并行度。默认情况下,并行度是由框架决定:使用与上游链式算子相同的并行度。 |
| sink.ignore.changelog | 可选 | false | Boolean | 忽略所有 RowKind 类型的变更日志,将它们当作 INSERT 的数据来采集。 |
| inlong.metric.labels | 可选 | (none) | String | inlong metric 的标签值,该值的构成为groupId={groupId}&streamId={streamId}&nodeId={nodeId}。 |
数据类型映射
| ClickHouse type | Flink SQL type |
|---|---|
| String | CHAR |
| String IP UUID | VARCHAR |
| String EnumL | STRING |
| UInt8 | BOOLEAN |
| FixedString | BYTES |
| Decimal Int128 Int256 UInt64 UInt128 UInt256 | DECIMAL |
| Int8 | TINYINT |
| Int16 UInt8 | SMALLINT |
| Int32 UInt16 Interval | INTEGER |
| Int64 UInt32 | BIGINT |
| Float32 | FLOAT |
| Date | DATE |
| DateTime | TIME |
| DateTime | TIMESTAMP |
| DateTime | TIMESTAMP_LTZ |
| Int32 | INTERVAL_YEAR_MONTH |
| Int64 | INTERVAL_DAY_TIME |
| Array | ARRAY |
| Map | MAP |
| Not supported | ROW |
| Not supported | MULTISET |
| Not supported | RAW |